目的
解决BERT模型的缺点
- 掩码比例的敏感性
- 处理序列最多512个token
三个模块
- 日志处理
- 模型微调
- 强化学习
日志处理
将日志解析成模板,称之为log key
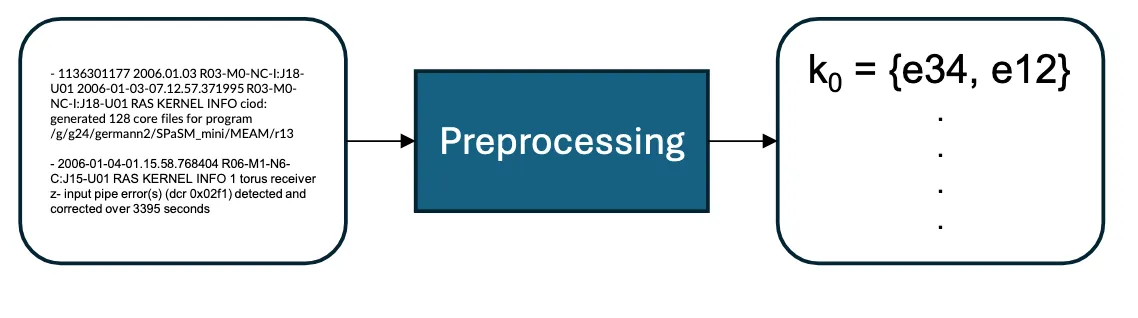
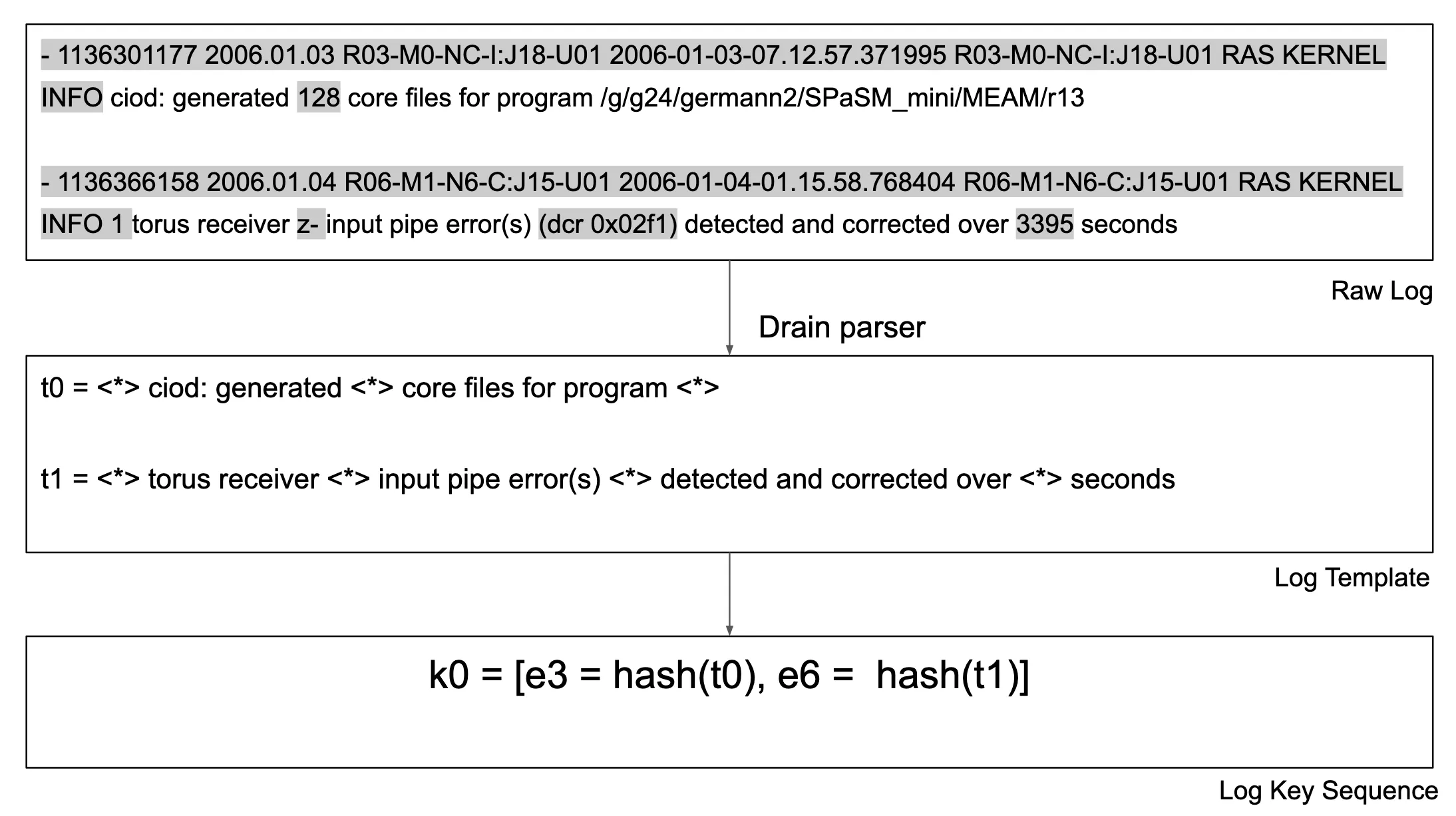
具体实现
使用Drain方法解析,解析之后将日志模板哈希化,映射到$(0,1,2,…,n)$的空间上,n是最大的模板数量,由这些日志模版组成一系列日志序列($k_0,k_1,k_2,…,k_m$)一共有$m$个日志序列,其中$m$取决于原始日志的划分方法。
模型微调
将log key序列编码作为训练集微调模型
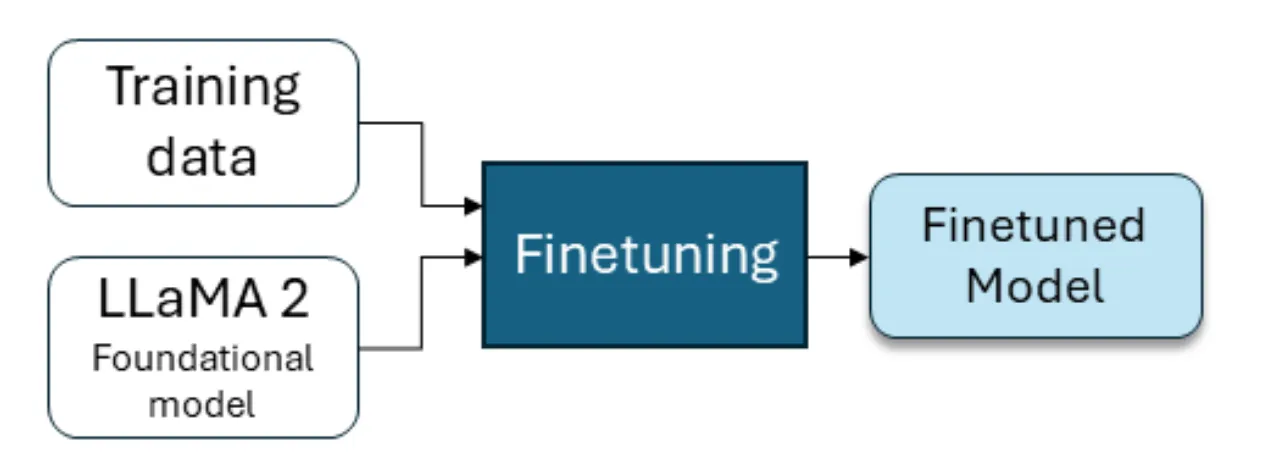
具体实现
将$BGL,Thunderbird,HDFS$解析后的正常log key作为数据集进行微调训练,相当于给定一条log key序列$k$,包括$e_0,e_1,…,e_t$,预测$e_{t+1}$,
强化学习
将微调后的模型再进行强化学习训练

具体实现
经过模型微调之后,模型能够对日志进行学习输入输出模式,也就是说给出log key序列能够预测很好的预测下一个词,现在进行异常检测,使用REINFORCE算法进行强化学习,引入$Top-K$选择,模型输出概率最高的$K$个候选log key,若真实下一个键$e_{t+1}$出现在这个列表中,则视为“正常”,否则“异常”。 (这部分强化学习待填坑)
数据集划分
- BGL:包括alert日志(异常)和non-alert日志(正常),一共4,747,963条日志,包括348,460条异常日志,采用60的滑动窗口进行分组组成日志序列。
- Thunderbird:选取前20,000,000条日志,包括758,562条异常日志,和BGL一样采用60的滑动窗口进行分组组成日志序列。
- HDFS:一共11,172,157条日志,包括284,818条异常日志. 按照session IDs进行分组组成日志序列。
结果
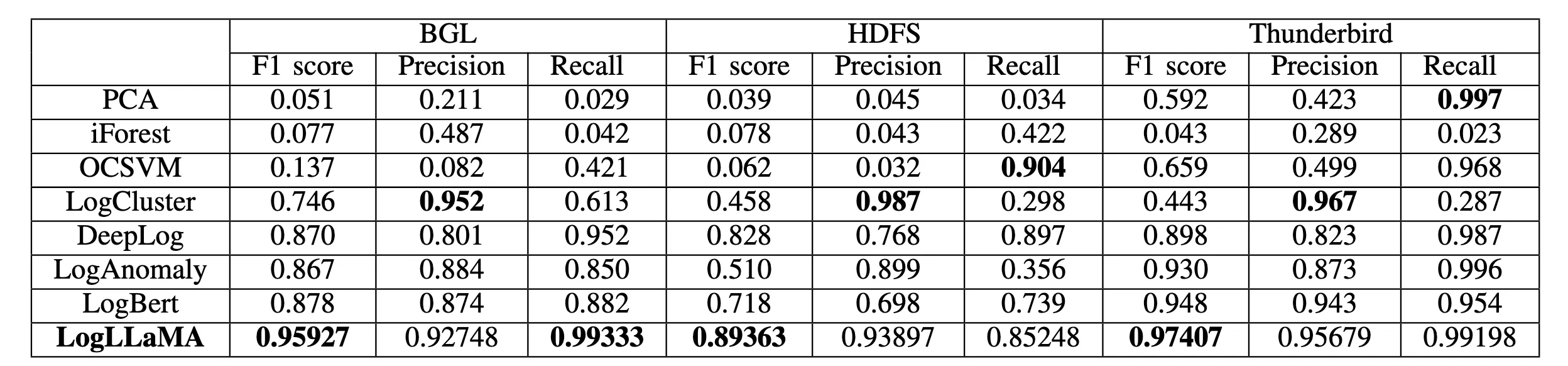
评价
纯纯浪费时间,读了以后,发现baseline是几年前的玩意,而且没什么创新点,将BERT模型换成LLaMa2,还加了个最老版本算法的强化学习,而不是最新的PPO、SAC。