目的
以往深度学习方法通常分为基于重构的方法和基于二分类的方法
- 基于重构的方法:异常通常难以被重构(deeplog、LogAnomaly、LogAttn、GAN)
- 基于二分类的方法:通常需要标签来训练最终分类为正常还是异常(LayerLog、LogRobust、CNN、logGD)
随着大语言模型的发展,模型的泛化能力得到大幅度发展。
- 基于提示词工程的方法利用大语言模型的零样本/少样本能力,存在一个问题,这种通用大模型很难对特地的数据集定制解决方法,导致检测性能次优。(loggpt、RAGLog
- 基于微调的方法将大语言模型集成到深度神经网络中,并使其适应用户特定数据集。(LogBERT、LAnoBERT、NeuralLog、
然而,这些方法面临诸多挑战,如语义理解有限、大语言模型利用不充分(仅依赖大语言模型进行语义信息提取),以及对输入数据格式考虑不足,可能导致内存溢出。
方法
logLLM基于微调的方法,使用正则化预处理日志,用BERT提取语义向量,用LLaMA分类日志序列,使用projector来对其BERT和LLaMA的向量空间,
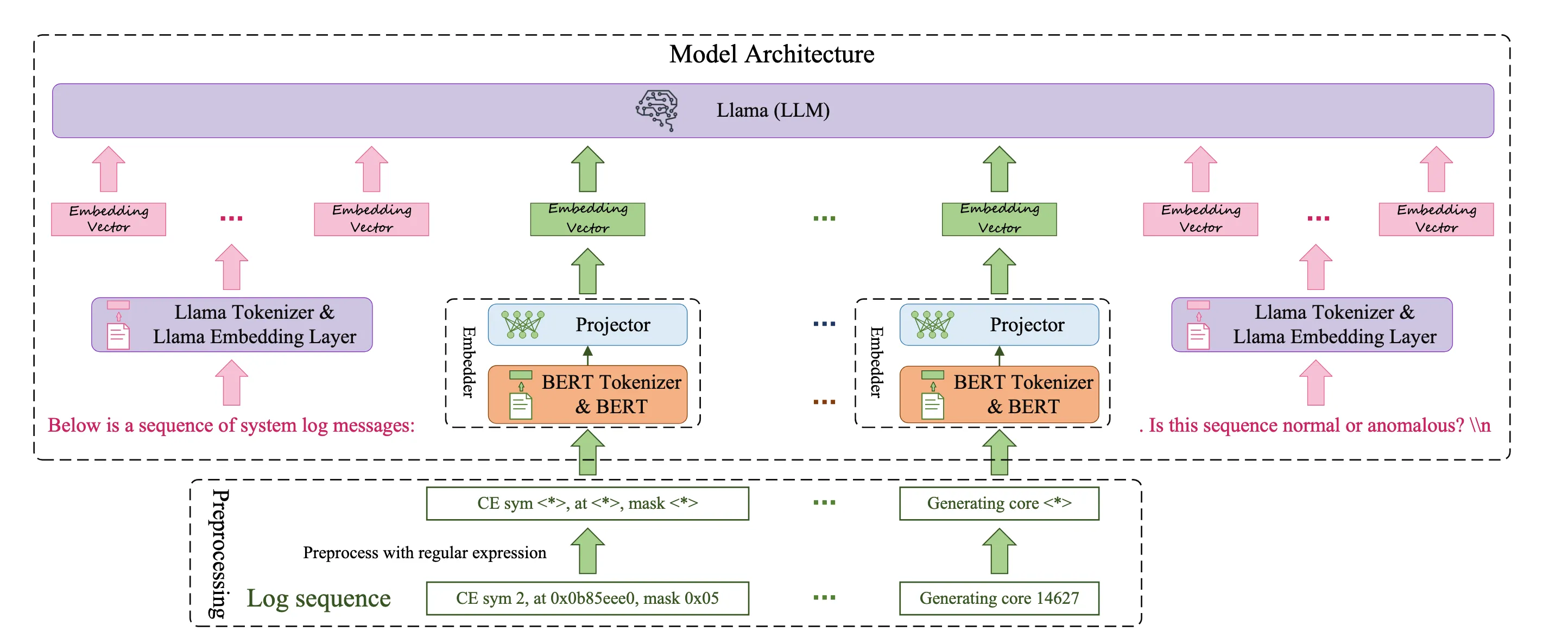
模块
-
日志解析 使用正则解析,因为Drain和Spell对于不稳定的日志不是总能处理所有日志序列,尤其是OOV问题,会导致语义缺失。
-
模型 包括BERT、Projector、Llama 其中Projector是一个线性层,可以将BERT向量化后的向量投影为Llama向量输入,$C ∈ R^{N×d_{BERT}}$转换成$E ∈ R^{N×d_{Llama}}$
再插入A向量和Q向量 A向量:Below is a sequence of system log messages: Q向量:. Is this sequence normal or anomalous? 最终$[E1||E||E3] ∈ R^{(A+N+Q)×d_{Llama}}$丢进去训练。
数据划分
先按照80%训练集,20%测试集划分,之后在训练集中按照随机采样、不放回少数样本达到30%(超参数),测试集不变
消融实验
作者做了一个解析模板的消融实验,发现使用正则解析F1分数总是最高

评价
让LLM做异常检测,算是常规做法,没有什么方法创新。